
Deep Learning - Convolutional Neural Networks
CNN
Convolutional Neural Networks (CNNs)

Convolution layer
1. Filter (Kernel)
是將輸入圖片與特定的 Feature filter 做卷積運算
將下圖 input image 每 3x3 個矩陣相乘後再相加,依序做完整張表
5d4f)
原本的 input image 為 6x6,filter 為 3x3,產生的 feature map 會是 4x4,
設 input image size 為
filter size 為
output image size 為
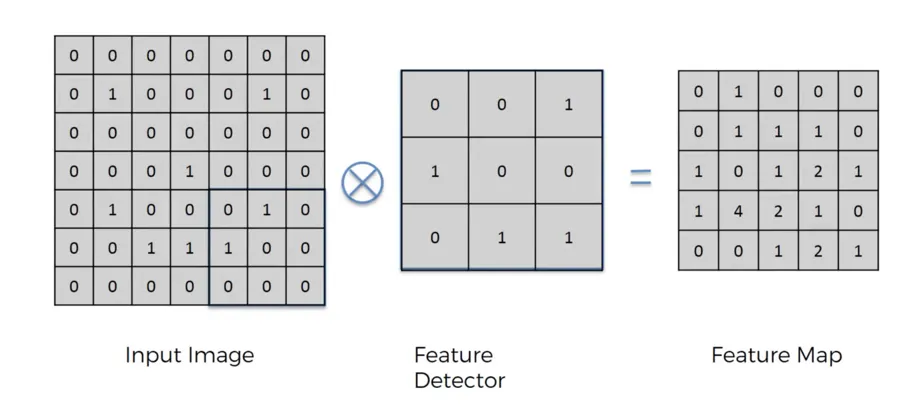
filter 的目的是萃取出圖片當中的一些特徵
2. Padding
因為做捲積會導致圖片邊緣的特徵被丟掉
並且會壓縮原有 input image
因此在圖片邊緣外層 padding 一圈 0,可以解決以上問題,讓輸出圖的大小和輸入圖一樣
設 padding layer 有多少層為 p
ex: 如果 filter 是 5x5,就會有 2 layers of zero 被加在圖片邊緣外
Same convolution
讓輸出圖和輸入圖大小相同,做以上 padding 方法
Valid convolution
不做 padding
3. Stride
stride 控制 filter 做捲積運算的時候每次移動多少格
output size 為
ex: filter 為 3x3,做 valid convolution 在 7x7 的 input image,stride 為 2
則輸出圖片大小為
Convolutions Over Volumes
立體的捲積運算
imput size = nxn
filter size = fxf
stride = s
padding = p
output image size =
ex:
imput size = 6x6x3
filter size = 3x3x3
stride = 1
padding = 0
n_c’ = 2
output size = 4 x 4 x 2
Pooling layer
池化層通常用於減少輸入量,從而加快計算速度
如果 input of pooling layer 是
output 的大小就是
Pooling 有 Max Pooling 和 Average Pooling,通常用 Max Pooling
Max Pooling
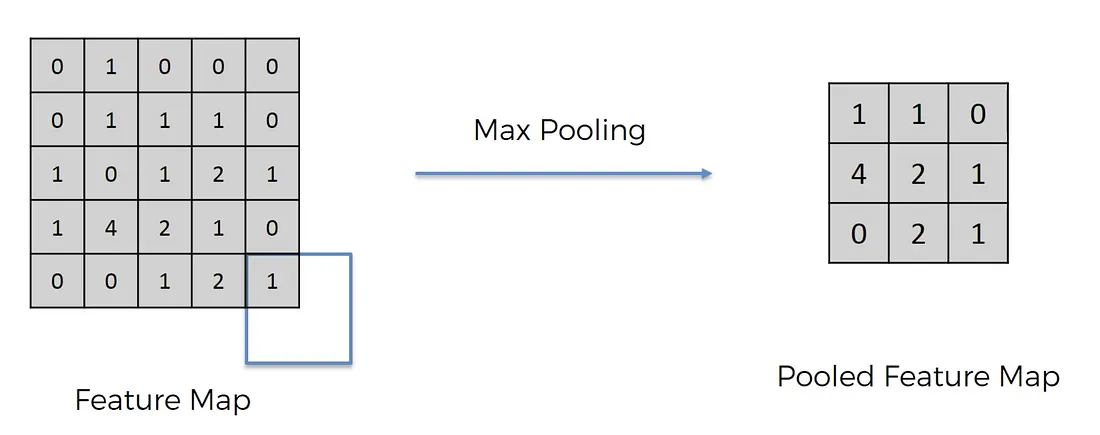
圖片來源
取每一格 pixel 的最大值那格
Flattening

把多維的矩陣拉長成一條直線,壓扁,才能被全連接層的神經元接收
Fully connected layer
將捲積層與池化層輸出的特徵輸入的全連接層,調整權重以達到分類的結果

GAN
Generative Adversarial Networks (GANs)

Transformer Model
- encoder-decoder structure
- self-attention without relying on recurrence and convolutions to generate an output