
Machine Learning - Underfitting, Overfitting and L1 L2 Regularization
Underfitting, Good fit and Overfitting
Underfitting
資料學得不夠好
可能因為模型訓練的時間不足(epoch 過少),或模型複雜度不足(神經網路結構過於簡單)導致
Good fit
資料學得剛剛好,你的模型很讚
Overfitting
過度擬合,模型能很好的預測訓練期間所用的 label,但實際應用在不同資料集時卻經常出錯
代表這個模型過度學習訓練資料集的資訊,以至於只會這個訓練資料集的 label

Training Error & Validation Error
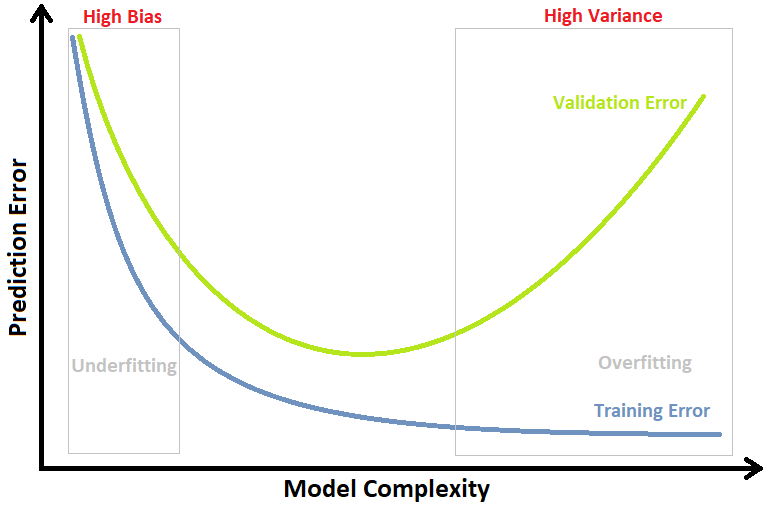
當模型複雜度偏向簡單(圖片中偏左側),Training Error 和 Validation Error 都很高,代表模型處於 underfitting 狀況
當模型複雜度過於複雜(圖片中偏右側),代表模型過度擬合 Overfitting Training Dataset,以致 Training Error 變得很低,但 Validation Error 卻飆得很高
因此,要選擇合適的模型指標,使模型在合適的時刻停止訓練
我的 Model Performance Assessment 相關文章
Machine Learning - Confusion Matrix
Machine Learning - Cross-Validation
Regularization
正規化,把複雜的模型倒退回簡單的模型
可以解決 overfitting 過度學習的問題,把複雜的參數減少
譬如下圖模型因 overfitting 學習成藍線,但預期為黑線
圖片來源
正規化的數學是透過在原先的 loss function 後增加一個正規化的 term,這個 term 不考慮 bias
L1

L1 正規化是把模型裡所有的參數都取絕對值
因為絕對值無法微分,所以把 >0 微分成 1,<0 微分成 -1,以 sign 函數表示
L1 正規化讓沒有用的權重設為 0,留下模型認為重要的權重
有可能導致 0 權重,因刪除許多特徵而使模型稀疏
L2

L2 正規化把模型裡所有的參數都取平方求和
把此 term 加入至新的 loss function 去對每個參數 wi 做偏微分後,會發現每次更新參數 wi 時,其實就是在 wi 前乘上一個很接近 1 的值
當更新參數 wi 次數越多,wi 會越接近 0 (但不會等於 0)
L2 正規化會讓 w 每次都變小一點,這被稱為權重衰減 weight decay
讓模型簡化,但不會只留下某個權重,而是削弱所有權重
會對越大的權重造成更大的影響,將使權重值保持較小