
Machine Learning - Cross-Validation & Holdout Method
通常深度學習訓練資料集都是大資料集,較常用 3-way holdout method (train/validation/test split)
2-way holdout method (train-test split)
train-test split 適合大資料集
Train Dataset: 用於訓練模型
Test Dataset: 用於評估學習模型的性能
也就是把整個資料集切成 Train Dataset 和 Test Dataset
3-way holdout method (train/validation/test split)
train/validation/test split 也適合大資料集
可能會切例如 60% Train/20% Validation/20% Test

Train set error = Bias
Validation set error = Bias + Variance
Bias = Train set error
Variance = Validation set error - Train set error

Note:
High Bias and High Variance
同時 underfitting 又 overfitting
Bias and Variance
bias-variance tradeoff: 平衡 bias 和 variance,使模型可以泛用在各種未見過的資料
Bias Error
Bias Error 是簡化模型近似真實事件問題時引入的
有著 high bias 的模型會導致模型 underfitting
也就是對資料特徵的抓取很不精準
Variance Error
Variance Error 是對訓練資料集波動敏感度的誤差
有著 high variance 的模型過於複雜,可能會抓取到訓練資料集的 noise,導致 overfitting
Cross-Validation 交叉驗證
機器學習模型的資料集,通常會切割成 80% 訓練集(Training Dataset)與 20% 驗證集(Validation Dataset)
Training Dataset 用來訓練整個機器學習模型,Validation Dataset 用來驗證這個模型訓練得好不好
因為在小資料集取一小部份當驗證資料,很難具有代表性,可能會剛好抽到一部份符合模型的訓練,又可能一部份無法符合模型
因此使用 Cross-Validation 交叉驗證是一個比較有效的評估模型的指標
K-fold Cross-Validation
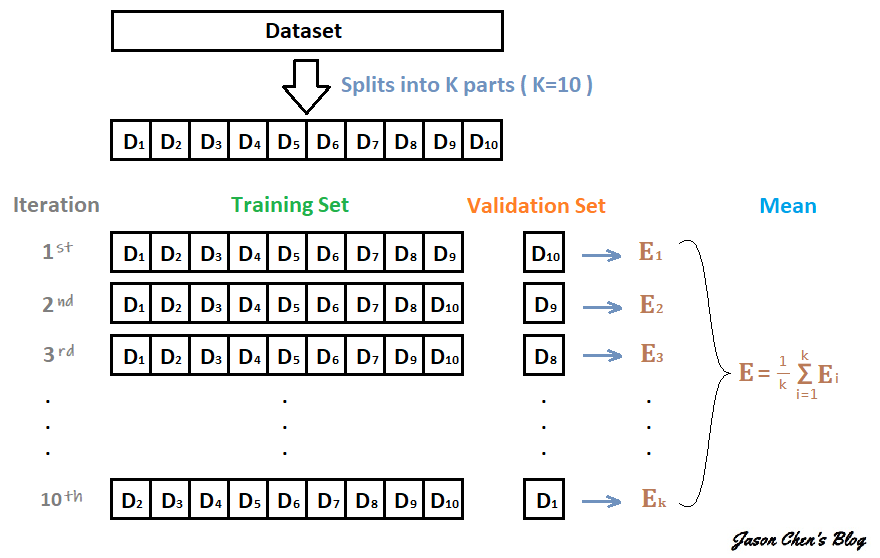
K-fold 和 KNN 的 K 一樣,代表不指定的數字
K-fold 的意思是把資料集 “折”、拆分成幾個部份
K-fold Cross-Validation 就是將資料集拆成 K 份互相做交叉驗證
方法:
- 把其中 K-1 份當作訓練集,剩下的那 1 份當作驗證集,算出一個 Validation Error
- 把從沒當過驗證集的資料中挑出一份當作驗證集,剛剛當過驗證集的資料加回訓練集,維持 K-1 份作訓練,1 份作驗證
- 如此反覆直到每份資料都當過驗證集,這樣會執行 K 次,算出 K 個 Validation Error
- 把這 K 個 Validation Error 做平均,用他們的平均分數來判斷模型好壞

每份被切割的資料都會當 k-1 次訓練資料、1 次驗證資料
Reference
- Hundred-Page Machine learning Book by A. Burkov
- 黃貞瑛老師的機器學習課程 - Model Evaulation
- 【機器學習】交叉驗證 Cross-Validation